An Honest Look at Kubernetes Dynamic Resource Allocation
Tim Nichols
CEO/Founder

What Is Kubernetes Dynamic Resource Allocation (DRA)?
Optimizing Kubernetes resources for reliability and cost is a constant pain for engineering teams. The rise of hardware like GPUs, TPUs, and FPGA has both increased the importance of precise, timely resource management and increased its difficulty. Building a GPU node pool remains incredibly expensive, and accessing it requires vendor-specific device drivers.
Dynamic Resource Allocation (DRA) simplifies resource management by generalizing the concepts of the Persistent Volume API to these new resources - you can describe what hardware your workload needs and kube-scheduler will try to get it for you.
Why is this special?
- Unifying operations under Kube-scheduler simplifies your stack (no third-party drivers) and can improve scheduling latency
- Specifying your workload’s precise needs with DRA can improve your workload’s availability, efficiency and performance.
- Compute teams spend a lot of time on scheduling, binning and packing. Write a DRA manifest once and you can deploy the same workload to multiple clusters across device types. It’s a huge workflow improvement.
DRA was the talk of the town at Kubecon EU. Today DRA is in beta, but it's expected to go GA in the upcoming 1.34 release.
How DRA works
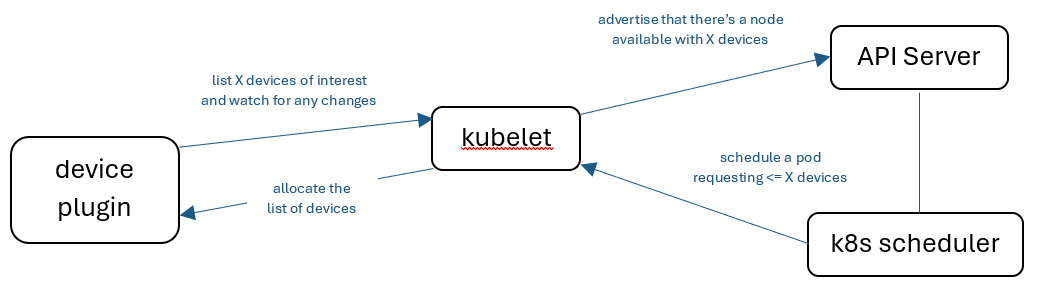
DRA has four components:
- An API for describing resources. Generally this should be provided in the form of DRA drivers by the device manufacturer.
- An API for pods to request resources. Pods can request resources based on the attributes that are provided in the DRA drivers such as minimum amounts of GPU memory or cores.
- A kube-scheduler plugin that allows the scheduler to use the DRA APIs to match pods to nodes that have the resources requested by the pods.
- A Kubelet API that makes the resources on the nodes available to the pods and containers they are assigned.
Dynamic Resource Allocation vs Node Affinity
If this concept seems familiar to Node Affinity that’s intentional - DRA is a more powerful, flexible toolset for today’s specialized workloads and hardware.
Here's a quick example that highlights the difference between DRA and Node Affinity:
Scheduling a Pod on a GPU Node with Node Affinity
Once drivers are installed, scheduling a pod on GPU Node with Node Affinities is a simple task:
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: gpu-type
operator: In
values:
- nvidia-a100
Node Affinities make it simple to set requirements for a pod directly in the pod definition. This makes it easy to get started, but options for optimizing resource usage are limited.
Scheduling a Pod on a GPU Node with DRA
Scheduling with DRA requires more work to get started but is more powerful and flexible once implemented.
First, create a ResourceClaimTemplate that the pods will use to create a ResourceClaim when they are instantiated:
apiVersion: resource.k8s.io/v1beta2 # This will change as the API is released to GA
kind: ResourceClaimTemplate
metadata:
name: gpu-claim-template
spec:
spec:
devices:
requests:
- name: req-0
exactly:
deviceClassName: resource.example.com # This depends on your DRA driver
selectors:
- cel:
expression: |-
device.attributes["resource-driver.example.com"].gpu.memory >= "10gi" &&
device.attributes["resource-driver.example.com"].num.cores >= "2"
This ResourceClaimTemplate is more complex than the requirements defined using Node Affinities, but it demonstrates the use of Common Expression Language (CEL) to make more complex requirements. The use of attributes makes selecting resources much easier. Rather than determining which GPUs on the nodes in your cluster are able to handle your job and then adding them to a list of Node Affinities, you can set requirements based on hardware specs, similar to regular pod resource requests.
apiVersion: v1
kind: Pod
metadata:
name: demo-pod
spec:
resourceClaims:
- name: gpu
resourceClaimTemplateName: gpu-claim-template
To summarize ....
DRA
- Pods can request devices based on hardware attributes such as a minimum amount of memory for a GPU
- Allows fractional and shared resources (depends on driver support)
- New (Beta) with limited support and resources.
Node Affinity
- Resources must be requested by model
- Devices cannot be shared between containers
- Stable, widely supported and simple
Top DRA Talks at KubeCon EU
At KubeCon EU 2025 this past April, DRA was a frequent topic at both talks and coffee breaks.
Here are some of our favorite presentations from KubeCon EU 2025 for understanding DRA and potential applications.
- More Nodes, More Problems: Solving Multi-Host GPU/TPU Scheduling With Dynamic Resource Allocation - John Belamaric & Morten Torkildsen, Google: Provides a short intro to DRA and provides easy to understand examples of how it works.
- GPU Sharing at CERN: Cutting the Cake Without Losing a Slice! - Diana Gaponcic, CERN: Explains a practical application for DRA, handling sharing GPU resources between research groups.
- Uncharted Waters: Dynamic Resource Allocation for Networking - Miguel Duarte Barroso, Red Hat & Lionel Jouin, Ericsson Software Technology: Shows how DRA can be used for devices other than GPUs or TPUs, in this case networking devices.
What’s next for you and DRA
Frankly, DRA will be overkill for many infrastructure teams. Before you pilot DRA you should ask yourself three questions.
- Are you working with complex hardware for AI or HPC?
- What’s the shape and waste of your most expensive AI / GPU / HPC workloads … is there room for optimization?
- How much time do you spend managing Pod - Node assignment and scheduling?
The good news is that the answers to all of these questions can be approximated quickly and easily. And unless you're working at a Tech Unicorn ... the answer to all three is likely no. If the math says yes… then prepare for DRA to hit GA with Kubernetes v1.34 in August 2025.
Regardless Flightcrew will be there to help you size, scale and maintain your cloud infrastructure.
Tim Nichols
CEO/Founder
Tim was a Product Manager on Google Kubernetes Engine and led Machine Learning teams at Spotify before starting Flightcrew. He graduated from Stanford University and lives in New York City. Follow on Bluesky



