A Simple Guide for Setting Pod Disruption Budgets (PDBs) and Rollout Strategies
Sam Farid
CTO/Founder
Kubernetes has a variety of (somewhat confusing) controls for how to avoid downtime during planned and unplanned disruptions. We're sharing our internal decision tree for simple yet effective configuration to minimize downtime across many common scenarios.
Why PDBs and Rollout Strategies Matter
Kubernetes will happily evict or restart pods as long as it can still schedule another. That default behavior is great for stateless, retry-friendly workloads, and potentially lethal for single-replica APIs or quorum-based systems. Pod Disruption Budgets (PDBs) protect against voluntary disruptions like node drains or cluster upgrades by ensuring a minimum number of pods remain available. Meanwhile, rollout strategies control how your application upgrades when you deploy new versions. Get either one wrong and you pay in either degraded SLOs or stalled automation.
Key Configs
Pod Disruption Budgets
- minAvailable or maxUnavailable: Hard limits on simultaneous voluntary evictions. Only set one or the other
- These percentages round UP to the nearest integer. For example, a maxUnavailable of 25% on a deployment with 1 pod will mean that pod can be disrupted.
Deployments
- strategy.type: Either RollingUpdate (default) or Recreate
- strategy.rollingUpdate.maxSurge: Extra pods allowed during update (default: 25%)
- Higher values speed up rollouts but require more resources
- strategy.rollingUpdate.maxUnavailable: Pods that can be unavailable during update (default: 25%)
- Set to 0 for zero-downtime updates (requires maxSurge > 0)
StatefulSets
- updateStrategy.type: Either RollingUpdate (default) or OnDelete
- updateStrategy.rollingUpdate.partition: Freeze the first N ordinal replicas, keeping them on the old version
Other Relevant Configs
- Horizontal Pod Autoscalers (HPAs) cannot scale below the PDB minimum, so as shown below, it's important to make sure these place nicely together.
- Other settings may affect Pod readiness, such as minReadySeconds, progressDeadlineSeconds, and readinessProbe. These tend to be specific to the application itself and won't need to be set in all cases.
- Spot instance cycling is an "involuntary" disruption, so PDBs can only buy time but not prevent the node terminations.
Decision Tree
Generally, the strategy here is to protect uptime for critical services, and be more lenient with batch services to accelerate maintenance. The decision tree below shows how to accomplish this in different setups and scenarios:
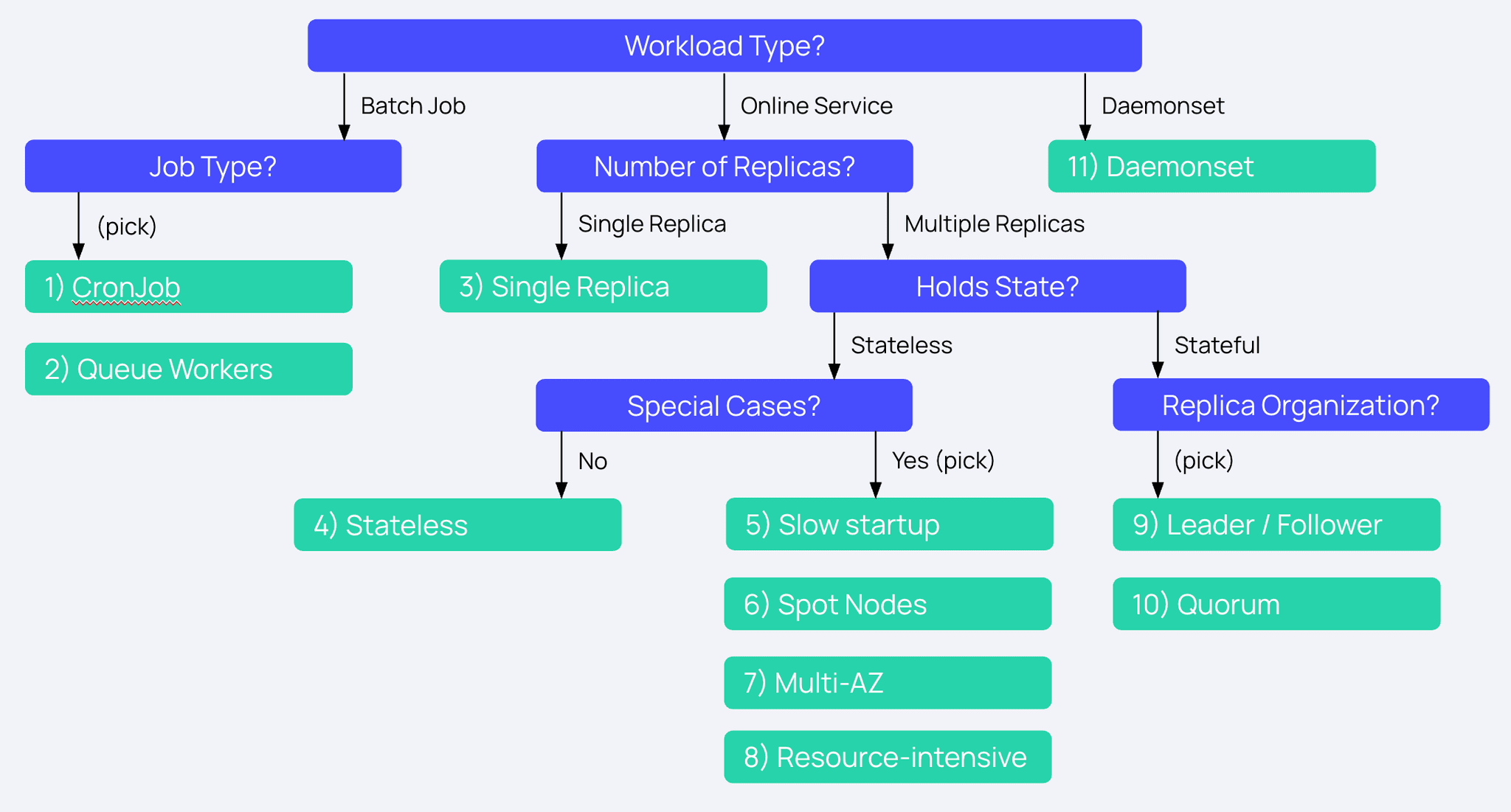
- (Batch) One-off Jobs / CronJobs
- Configuration:
- No PDB needed
- Rationale:
- No user traffic, so failures can simply retry
- Gotchas:
- Ensure Job has appropriate backoffLimit, otherwise kubelet may loop forever
- Consider setting activeDeadlineSeconds to prevent indefinite hangs
- Configuration:
- (Batch) Queue Workers (>=2 replicas, can tolerate interruption)
- Configuration:
- PDB: maxUnavailable:50%
- Rollout: maxSurge**:1, maxUnavailable:50%
- HPA: Add downscale stabilization window (>=5m)
- Rationale:
- Workers ack/retry from a queue, losing half cuts throughput but preserves correctness
- Limited surge to minimize resource usage while allowing upgrades
- Gotchas:
- Upgrades can deadlock if HPA scales to 1 replica, so enforce HPA.minReplicas:2
- Ensure your queue system handles message retries appropriately
- Configuration:
- Single-Replica Services
- Configuration:
- PDB: minAvailable:0 (allows controlled drains)
- Rationale:
- Can't guarantee uptime through eviction with only one replica
- Skip strict PDB protection, focus on graceful termination and fast health checks
- Gotchas:
- Ensure readiness gates + preStop hook >= gracefulShutdown period
- To forbid a drain entirely, set maxUnavailable:0 (and delete the PDB when downtime is acceptable)
- Configuration:
- Stateless Web/API on On-Demand Nodes
- Configuration:
- PDB: maxUnavailable:25%
- Rollout: maxSurge:25%, maxUnavailable:0
- Rationale:
- Fewer surprise evictions: trade some headroom (surge) for rollout speed
- maxUnavailable:0 guarantees no brown-outs during deployments
- Gotchas:
- Zero unavailability can slow down rollouts if new pods are slow to become ready
- Ensure your readiness probes accurately reflect service health
- Configuration:
- Services with Slow Startup/Initialization
- Configuration:
- PDB: maxUnavailable:25%
- Rollout: maxSurge:25%, minReadySeconds:30-120
- Rationale:
- Ensures new pods are fully ready before counting toward availability
- Prevents premature termination of old pods during rollout
- Gotchas:
- Increase progressDeadlineSeconds for large images
- Set minReadySeconds higher than your longest expected initialization time
- Monitor resource usage during rollouts as you'll have 25% more pods temporarily
- Configuration:
- Services on Spot / Preemptible Nodes
- Configuration:
- PDB: minAvailable:80%
- Rollout: maxSurge:30%, maxUnavailable:0
- Add priorityClass and/or over-provision by 20-30%
- Rationale:
- Preemption causes involuntary churn; high minAvailable plus surge buffer buys time
- Extra capacity ensures replacement pods can schedule quickly
- Gotchas:
- Over-provision cluster autoscaler capacity by 30% so the surge pods can be scheduled when needed
- Configuration:
- Multi-AZ Stateless Services
- Configuration:
- PDB: maxUnavailable: less than the percent in a single AZ (typically <=33%). So for example: in 3 AZs, keep maxUnavailable: 30% (one AZ-worth of pods)
- Rollout: maxSurge:25%, maxUnavailable:0
- Add topologySpreadConstraints for even zone distribution
- Rationale:
- Ensures service remains available even if an entire zone is lost
- No unavailability during deployments for maximum reliability
- Gotchas:
- Calculate minAvailable per-zone; don't let a zone drain drop below quorum
- Ensure your load balancer respects availability zones for backend selection
- Configuration:
- Resource-Intensive Services
- Configuration:
- PDB: maxUnavailable:10%
- Rollout: maxSurge:10%, maxUnavailable:0
- Rationale:
- Limited resources mean you can't afford large surge capacity
- Slow startup requires extended probe timeouts to prevent premature restarts
- Gotchas:
- May require dedicated nodes with node affinity rules
- Increase startupProbe and livenessProbe timeouts
- Configuration:
- Stateful Services with Leader/Follower Roles
- Configuration:
- PDB for followers: maxUnavailable:1
- PDB for leaders: maxUnavailable:0
- Rollout: updateStrategy.rollingUpdate.partition=<leaders-count>
- Rationale:
- Prevents disruption of critical leader pods during updates
- Updates followers first to verify changes before touching leaders
- Gotchas:
- Partition is essential because rolling updates ignore the PDB
- May require multiple StatefulSets with different configurations for leaders vs followers
- Leader pods should use pod anti-affinity to prevent co-scheduling
- Configuration:
- Quorum-Based Systems (etcd, Kafka, ZooKeeper)
- Configuration:
- PDB: maxUnavailable:1 (never more except during planned maintenance)
- Rollout: updateStrategy.rollingUpdate.partition=N-1 for testing
- Rationale:
- Quorum can safely lose one member but no more
- PDB prevents extra disruption; partition rollout updates one pod at a time
- Gotchas:
- Cluster-level drains still respect the PDB, so setting maxUnavailable:0 can block kube-upgrade operations
- For major version upgrades, consider manual coordination
- Configuration:
- Daemonsets
- Configuration:
- PDB: None
- Use updateStrategy.rollingUpdate.maxUnavailable:10%
- Rationale:
- Daemonsets typically provide node-level services that can temporarily go down
- Gotchas:
- Daemonsets automatically scale with your cluster size
- Ensure preStop hooks for graceful termination
- Configuration:
Example
Here's a quick example showing the actual configs for the spot node scenario mentioned above:
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: web-spot
spec:
minAvailable: 80% # Keep 80% available during voluntary disruptions
selector:
matchLabels:
app: web
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: web
spec:
replicas: 10 # Higher replica count for redundancy
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 30% # Allow 30% extra pods during updates
maxUnavailable: 0 # Never reduce capacity during updates
Test the Setup
- Test a PDB: kubectl drain <node-name> --ignore-daemonsets
- If disrupting the pods would exceed the PDB limit, Kubernetes will prevent the drain operation.
- Test a Rollout: kubectl rollout status deployment/<deployment-name>
- Watch pods destroyed and created in realtime to confirm availability.
Key Takeaways
There are many possible settings for PDBs and rollout strategies, but in practice there's really only going to be one "right" answer for a workload - it's more of a science than an art when you crawl the decision tree and keep the caveats and gotchas in mind.
If all this sounds like a lot of work to do manually, Flightcrew can automate proper PDB and Rollout Strategy implementation through GitHub PRs. If that sounds interesting, sign up for a trial or shoot us a note at hello@flightcrew.io and we can help you get set up.
Thanks for reading!
Sam Farid
CTO/Founder
Before founding Flightcrew, Sam was a tech lead at Google, ensuring the integrity of YouTube viewcount and then advancing network throughput and isolation at Google Cloud Serverless. A Dartmouth College graduate, he began his career at Index (acquired by Stripe), where he wrote foundational infrastructure code that still powers Stripe servers. Find him on Bluesky or holosam.dev.



